主要涉及到下面几篇论文
- Building end-to-end dialogue systems using generative hierarchical neural network models
- A Hierarchical Latent Variable Encoder-Decoder Model for Generating Dialogues
- Generating Sentences From a Continuous Spaces motivation
HRED
HRED 在之前经典的端到端聊天模型 提到过,这里拎出来再具体分析一下。
传统 Seq2Seq 在对话任务上对上下文依赖考虑有限,Building end-to-end dialogue systems using generative hierarchical neural network models 论文提出了一种 分层 RNN 结构 - HRED(Hierarchical Recurrent Encoder-Decoder),能同时对句子和对话语境(上下文)进行建模,来实现多轮对话。
先来看一下如果不使用分层 RNN,在传统 Seq2Seq 模型基础上,如果我们想得到 context 信息应该怎么做。
第一个想法是将上一个句子的 final state 作为下一个句子的 initial state,然后将句子信息不断传递下去,这样的话 context vector 里的信息会在 propagation 的过程中会被新句子的词语逐步稀释,对信息/梯度的传播极不友好。
因此为了让信息更好的传递,我们可能会考虑把 final state 传递到下一个句子的 last state,而不是 initial state,然后用拼接或者非线性的方法来表达之前的和当前的句子信息。
更干脆的,直接将语境中的多个 utterance vector 提取出来再用一个 RNN 来处理,捕捉 context 信息,这就有了分层 RNN。
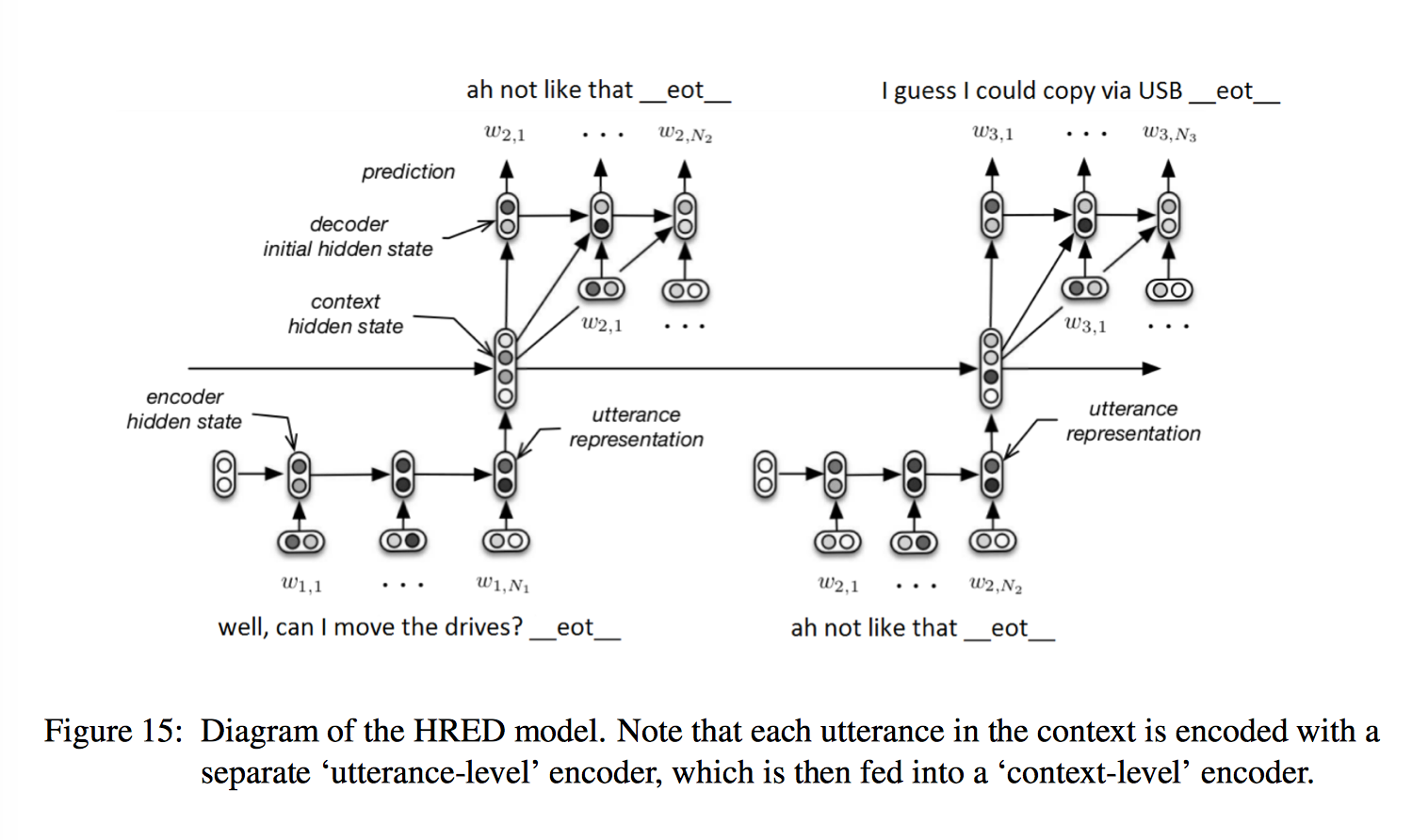
简单来说,HRED 在传统 encoder-decoder 模型上,额外增加了一个 encoder,相比于普通的 RNN-LM 来说,考虑了 turn-taking nature,能够对上下文进行建模,减少了相邻句子间的计算步骤,有助于信息/梯度的传播,从而实现多轮对话。整个过程有下面三个阶段:
- encoder RNN
第一个 encoder 和标准的 seq2seq 相同,将一句话编码到固定长度的 utterance vector,也就是 RNN 的 last hidden state
encoder RNN 或者说 utterance RNN 记忆的是对话的细节 - context RNN
n 个句子的 utterance vector 作为第二个 encoder 也就是 context-level encoder 各个时间上的的输入,对应长度为 n 的 sequence,产生一个 context vector 实现对语境的编码,也就是 RNN 的 output (注意这里不是 last hidden state)
context RNN 记忆的是更为全局的语义信息 - decoder RNN
上一个句子的 utterance vector 作为 response 的初始状态,目前为止产生的 context vector 和上一个单词的 word embedding 拼接作为 decoder 的输入
然而 HRED 相对于传统的 Seq2Seq 模型的提高并不明显,bootstrapping 的作用更加明显。一方面可以用 pre-trained word embedding,另一方面可以使用其他 NLP 任务的数据预训练我们的模型,使得模型的参数预先学到一些对自然语言的理解,然后再来学习聊天任务。
VHRED
先简单看一下 auto-encoder 的两个变体 dAE 和 VAE。
Denoising auto-encoder(dAE) 在输入数据引入一些随机噪声,要求 auto-encoder 去重构加噪声之前的原始观测值,来增加模型鲁棒性,避免过拟合。
而 Variational Autoencoder(VAE) 则是在中间层(hidden layer)引入噪音,来重构输入数据,因此 auto-encoder 出来的样本具有更高的全局性。
VHRED(Latent Variable Hierarchical Recurrent Encoder-Decoder Model),就是在 HRED 基础上引入了 VAE 的思想,不同的是在 reconstruction 时生成的是下一个 utterance 而不是原来的 input。
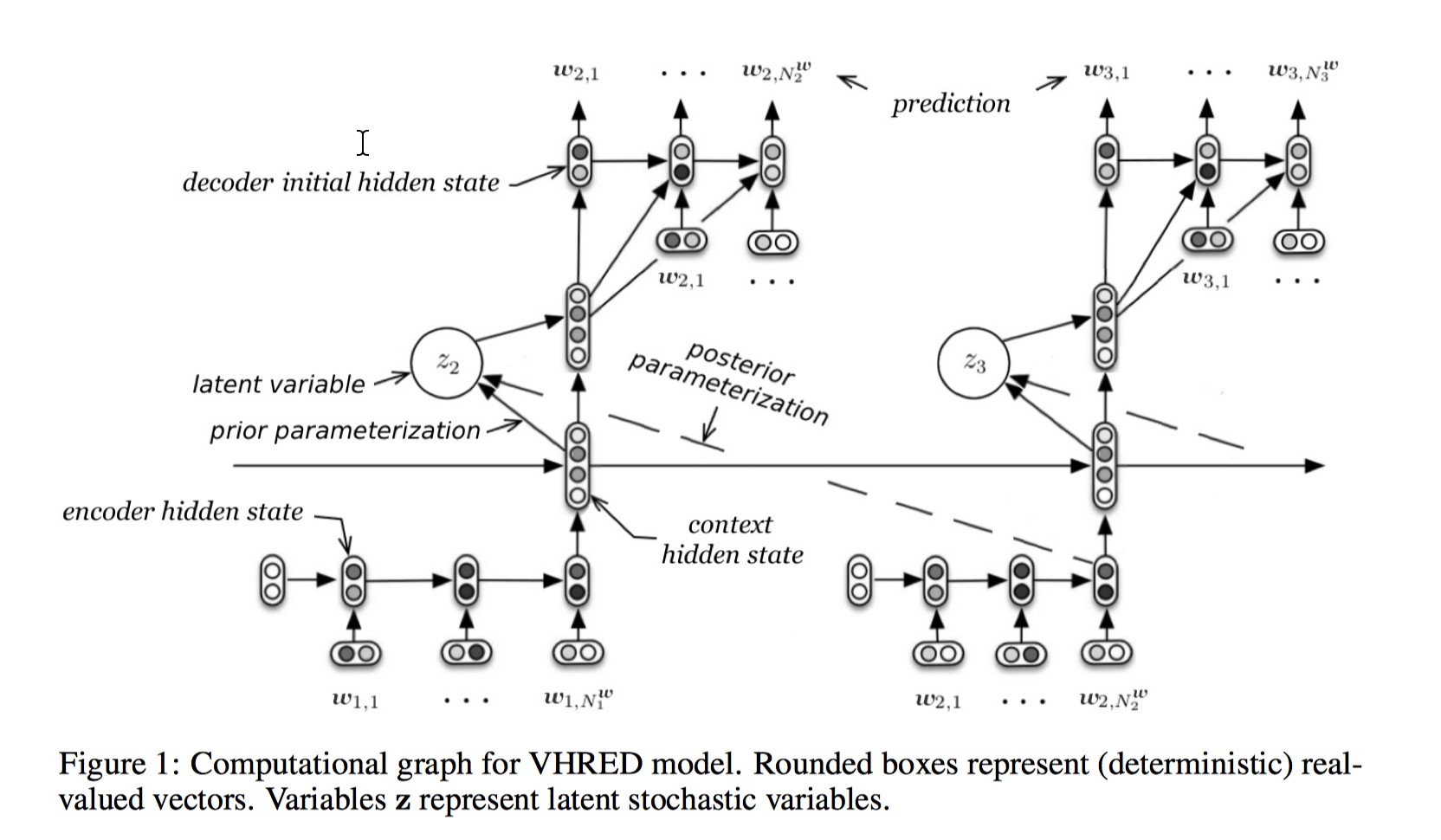
VHRED 是为了解决 RNNLM 和 HRED 很难产生有意义的、高质量的回复而提出的。传统 Seq2Seq 倾向于产生短的安全回答(safe response),因为它有确定性的编码和解码过程,着重拟合具体、有限的回复样本,缺少对 response 语义信息的理解。另外 decoder 时两个目标,一是生成下一个 token,二是占据控制真实输出路径的 embedding space 的一个位置,来影响之后 token 的生成,而由于梯度衰减的影响,模型会更聚焦第一个目标,response 的产生更容易限于 token level,尤其对于 high-entropy 的句子,模型更偏好短期预测而不是长期预测,所以模型很难产生长的、高质量的回复。
VHRED 针对这个问题引入了全局(语义层面)的随机因素,一是能增强模型的 robustness,二是能捕捉 high level concepts。Latent variable 使得 response 不再和一个/几个固定的句子绑定,鼓励了回复的多样性。
和 HRED 不同的是,VHRED 在第二个 context RNN 产生 context vector c 后,由 c sample 了一些高斯随机变量 z(latent variable),期望值和标准差由 c 决定(前向网络+矩阵乘法得到 $\mu$,+矩阵乘法和 softplus 得到 $\Sigma$),高斯变量和 context vector 拼接就得到了包含全局噪声的 vector,作为每个时间的观测值,和 query vector 一起放到 decoder 里产生 response。
训练时,z 从后验采样,测试时由于 KL 已经把分布拉近,z 可以从先验采样。模型的训练技巧如 KL annealing 等借鉴了 Generating Sentences From a Continuous Spaces motivation 这篇论文的思想。
因为 z 是从 context state 计算出来的,latent variable 的期望值和标准差包含一些 high-level 的语义信息,更鼓励模型抽取抽象的语义概念。实验表明,HRED 能产生更长的回复,更好的 diversity。

